Spark Transformations, Actions and Lazy Evaluation.
Apache Spark RDD supports two types of Operations:
- Transformations
- Actions
A Transformation is a function that produces new RDD from the existing RDDs but when we want to work with the actual dataset, at that point Action is performed.
Transformations
Transformations when executed results in a single or multiple new RDD’s. Transformations are lazy operations meaning none of the transformations get executed until you call an action on Spark RDD. Since RDD’s are immutable, any transformations on it result in a new RDD leaving the current one unchanged, creating an RDD lineage.
There are two types are transformations
- Narrow Transformation
- Wide Transformation
Narrow Transformation
Transformations that dose not result in data movement between partitions are called Narrow transformations. Functions such as map(), flatMap(), filter(), union() are some examples of narrow transformation
Wide Transformation
Transformations that involves data movement between partitions are called Wide transformations or shuffle transformations. Functions such as groupByKey(), aggregate(), aggregateByKey(), join(), repartition() are some examples of a wide transformations.
Actions
Actions are methods to access the actual data available in an RDD. Action executes all the related transformations to get the required data. Functions such as collect(), show(), count(), first(), take(n) are examples of actions.
Lazy Evaluation
Lazy Evaluation in Sparks means Spark will not start the execution of the process until an Action is called. Once an Action is called, Spark starts looking at all the transformations and creates a DAG. DAG is sequence of operations that need to be performed in a process to get the resultant output. If Spark could wait until an Action is called, it may merge some transformation or skip some unnecessary transformation and prepare a perfect optimized execution plan.
Lets take an example,
We have an employee data set. First we will perform a filter() operation (Narrow Transformation) then orderBy() and groupBy() operations (Wide Transformations). After that we will show the dataframes (Action) and look at the resulting DAG.
df=spark.read.parquet("employee") #Transformations df_sal = df.filter("Salary > 6000") #1 df_exp = df_sal.filter("Experience_Years > 4") #2 df_age = df_exp.filter("Age < 55") #3 df_gen = df_age.filter("Gender=='Male'") #4 df_mumbai = df.filter("Location=='Mumbai'") #5 df_ordered = df.orderBy("Salary") #6 df_sal2 = df_ordered.filter("Salary > 6000") #7 df_exp2 = df_sal2.filter("Experience_Years > 3") #8 df_age2 = df_exp2.filter("Age > 30") #9 df_gen2 = df_age2.filter("Gender=='Female'") #10 df_pune_ord = df_gen2.filter("Location=='Pune'") #11 df_pune_grp = df_pune_ord.groupBy("Gender").sum("Salary") #12 #Action df_mumbai.show() #1 df_pune_grp.show() #2
Initially we have a job after reading the parquet file

After performing all 12 the Transformations, there is no additional job in the Spark UI.
After performing the first Action df_mumbai.show(), we can see a new job.


Instead of performing 5 different filter conditions as mentioned in transformations 1-5, spark executed a single optimized filter condition. Also only transformations 1-5 are executed and 6-12 are ignored as they are not related to df_mumbai dataframe. This is possible due the lazy evaluation of transformations. Since these transformations were narrow, no new stage was required as there is no data movement.
After performing the second Action df_pune_grp.show(), we can see two new jobs.
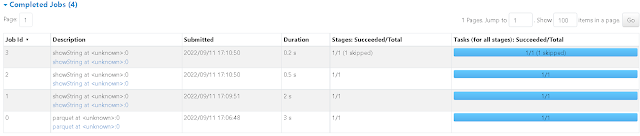
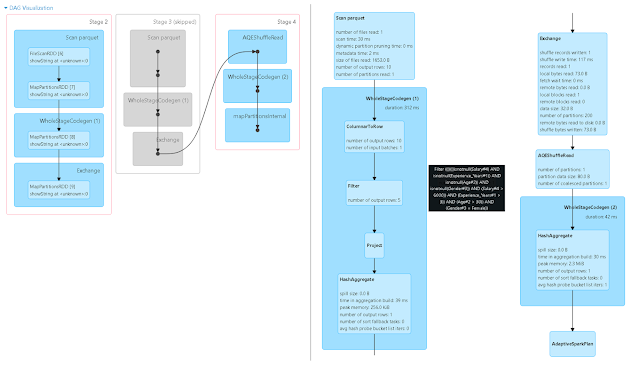
Here Stage 3 is skipped as those transformations are already performed in Stage 2. An important thing to notice here is orderBy() is performed after the filter conditions even tough it is mentioned first in the code (6). This reduces the data movement as there will be less records after the filter. For transformations 6-11 we can see only two Stages are created. This is because only 6 & 12 are wide transformations.
Comments
Post a Comment